
text
stringlengths 0
2k
| heading1
stringlengths 4
79
| source_page_url
stringclasses 183
values | source_page_title
stringclasses 183
values |
|---|---|---|---|
First let's define the UI and put placeholders for all the python logic.
```python
import gradio as gr
with gr.Blocks() as block:
gr.HTML(
f"""
<h1 style='text-align: center;'> Magic 8 Ball 🎱 </h1>
<h3 style='text-align: center;'> Ask a question and receive wisdom </h3>
<p style='text-align: center;'> Powered by <a href="https://github.com/huggingface/parler-tts"> Parler-TTS</a>
"""
)
with gr.Group():
with gr.Row():
audio_out = gr.Audio(label="Spoken Answer", streaming=True, autoplay=True)
answer = gr.Textbox(label="Answer")
state = gr.State()
with gr.Row():
audio_in = gr.Audio(label="Speak your question", sources="microphone", type="filepath")
audio_in.stop_recording(generate_response, audio_in, [state, answer, audio_out])\
.then(fn=read_response, inputs=state, outputs=[answer, audio_out])
block.launch()
```
We're placing the output Audio and Textbox components and the input Audio component in separate rows. In order to stream the audio from the server, we'll set `streaming=True` in the output Audio component. We'll also set `autoplay=True` so that the audio plays as soon as it's ready.
We'll be using the Audio input component's `stop_recording` event to trigger our application's logic when a user stops recording from their microphone.
We're separating the logic into two parts. First, `generate_response` will take the recorded audio, transcribe it and generate a response with an LLM. We're going to store the response in a `gr.State` variable that then gets passed to the `read_response` function that generates the audio.
We're doing this in two parts because only `read_response` will require a GPU. Our app will run on Hugging Faces [ZeroGPU](https://huggingface.co/zero-gpu-explorers) which has time-based quotas. Since generating the response can be done with Hugging Face's Inference API, we shouldn't include that code in our GPU func
|
The UI
|
https://gradio.app/guides/streaming-ai-generated-audio
|
Streaming - Streaming Ai Generated Audio Guide
|
GPU](https://huggingface.co/zero-gpu-explorers) which has time-based quotas. Since generating the response can be done with Hugging Face's Inference API, we shouldn't include that code in our GPU function as it will needlessly use our GPU quota.
|
The UI
|
https://gradio.app/guides/streaming-ai-generated-audio
|
Streaming - Streaming Ai Generated Audio Guide
|
As mentioned above, we'll use [Hugging Face's Inference API](https://huggingface.co/docs/huggingface_hub/guides/inference) to transcribe the audio and generate a response from an LLM. After instantiating the client, I use the `automatic_speech_recognition` method (this automatically uses Whisper running on Hugging Face's Inference Servers) to transcribe the audio. Then I pass the question to an LLM (Mistal-7B-Instruct) to generate a response. We are prompting the LLM to act like a magic 8 ball with the system message.
Our `generate_response` function will also send empty updates to the output textbox and audio components (returning `None`).
This is because I want the Gradio progress tracker to be displayed over the components but I don't want to display the answer until the audio is ready.
```python
from huggingface_hub import InferenceClient
client = InferenceClient(token=os.getenv("HF_TOKEN"))
def generate_response(audio):
gr.Info("Transcribing Audio", duration=5)
question = client.automatic_speech_recognition(audio).text
messages = [{"role": "system", "content": ("You are a magic 8 ball."
"Someone will present to you a situation or question and your job "
"is to answer with a cryptic adage or proverb such as "
"'curiosity killed the cat' or 'The early bird gets the worm'."
"Keep your answers short and do not include the phrase 'Magic 8 Ball' in your response. If the question does not make sense or is off-topic, say 'Foolish questions get foolish answers.'"
"For example, 'Magic 8 Ball, should I get a dog?', 'A dog is ready for you but are you ready for the dog?'")},
{"role": "user", "content": f"Magic 8 Ball please answer this question - {question}"}]
response = client.chat_completion(messages,
|
The Logic
|
https://gradio.app/guides/streaming-ai-generated-audio
|
Streaming - Streaming Ai Generated Audio Guide
|
for you but are you ready for the dog?'")},
{"role": "user", "content": f"Magic 8 Ball please answer this question - {question}"}]
response = client.chat_completion(messages, max_tokens=64, seed=random.randint(1, 5000),
model="mistralai/Mistral-7B-Instruct-v0.3")
response = response.choices[0].message.content.replace("Magic 8 Ball", "").replace(":", "")
return response, None, None
```
Now that we have our text response, we'll read it aloud with Parler TTS. The `read_response` function will be a python generator that yields the next chunk of audio as it's ready.
We'll be using the [Mini v0.1](https://huggingface.co/parler-tts/parler_tts_mini_v0.1) for the feature extraction but the [Jenny fine tuned version](https://huggingface.co/parler-tts/parler-tts-mini-jenny-30H) for the voice. This is so that the voice is consistent across generations.
Streaming audio with transformers requires a custom Streamer class. You can see the implementation [here](https://huggingface.co/spaces/gradio/magic-8-ball/blob/main/streamer.py). Additionally, we'll convert the output to bytes so that it can be streamed faster from the backend.
```python
from streamer import ParlerTTSStreamer
from transformers import AutoTokenizer, AutoFeatureExtractor, set_seed
import numpy as np
import spaces
import torch
from threading import Thread
device = "cuda:0" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
torch_dtype = torch.float16 if device != "cpu" else torch.float32
repo_id = "parler-tts/parler_tts_mini_v0.1"
jenny_repo_id = "ylacombe/parler-tts-mini-jenny-30H"
model = ParlerTTSForConditionalGeneration.from_pretrained(
jenny_repo_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
).to(device)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)
sampling_rate = model.audio_encoder.config.sampling_rate
f
|
The Logic
|
https://gradio.app/guides/streaming-ai-generated-audio
|
Streaming - Streaming Ai Generated Audio Guide
|
sage=True
).to(device)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)
sampling_rate = model.audio_encoder.config.sampling_rate
frame_rate = model.audio_encoder.config.frame_rate
@spaces.GPU
def read_response(answer):
play_steps_in_s = 2.0
play_steps = int(frame_rate * play_steps_in_s)
description = "Jenny speaks at an average pace with a calm delivery in a very confined sounding environment with clear audio quality."
description_tokens = tokenizer(description, return_tensors="pt").to(device)
streamer = ParlerTTSStreamer(model, device=device, play_steps=play_steps)
prompt = tokenizer(answer, return_tensors="pt").to(device)
generation_kwargs = dict(
input_ids=description_tokens.input_ids,
prompt_input_ids=prompt.input_ids,
streamer=streamer,
do_sample=True,
temperature=1.0,
min_new_tokens=10,
)
set_seed(42)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for new_audio in streamer:
print(f"Sample of length: {round(new_audio.shape[0] / sampling_rate, 2)} seconds")
yield answer, numpy_to_mp3(new_audio, sampling_rate=sampling_rate)
```
|
The Logic
|
https://gradio.app/guides/streaming-ai-generated-audio
|
Streaming - Streaming Ai Generated Audio Guide
|
You can see our final application [here](https://huggingface.co/spaces/gradio/magic-8-ball)!
|
Conclusion
|
https://gradio.app/guides/streaming-ai-generated-audio
|
Streaming - Streaming Ai Generated Audio Guide
|
Automatic speech recognition (ASR), the conversion of spoken speech to text, is a very important and thriving area of machine learning. ASR algorithms run on practically every smartphone, and are becoming increasingly embedded in professional workflows, such as digital assistants for nurses and doctors. Because ASR algorithms are designed to be used directly by customers and end users, it is important to validate that they are behaving as expected when confronted with a wide variety of speech patterns (different accents, pitches, and background audio conditions).
Using `gradio`, you can easily build a demo of your ASR model and share that with a testing team, or test it yourself by speaking through the microphone on your device.
This tutorial will show how to take a pretrained speech-to-text model and deploy it with a Gradio interface. We will start with a **_full-context_** model, in which the user speaks the entire audio before the prediction runs. Then we will adapt the demo to make it **_streaming_**, meaning that the audio model will convert speech as you speak.
Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). You will also need a pretrained speech recognition model. In this tutorial, we will build demos from 2 ASR libraries:
- Transformers (for this, `pip install torch transformers torchaudio`)
Make sure you have at least one of these installed so that you can follow along the tutorial. You will also need `ffmpeg` [installed on your system](https://www.ffmpeg.org/download.html), if you do not already have it, to process files from the microphone.
Here's how to build a real time speech recognition (ASR) app:
1. [Set up the Transformers ASR Model](1-set-up-the-transformers-asr-model)
2. [Create a Full-Context ASR Demo with Transformers](2-create-a-full-context-asr-demo-with-transformers)
3. [Create a Streaming ASR Demo with Transformers](3-create-a-streaming-asr-demo-with-transformers)
|
Introduction
|
https://gradio.app/guides/real-time-speech-recognition
|
Streaming - Real Time Speech Recognition Guide
|
First, you will need to have an ASR model that you have either trained yourself or you will need to download a pretrained model. In this tutorial, we will start by using a pretrained ASR model from the model, `whisper`.
Here is the code to load `whisper` from Hugging Face `transformers`.
```python
from transformers import pipeline
p = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
```
That's it!
|
1. Set up the Transformers ASR Model
|
https://gradio.app/guides/real-time-speech-recognition
|
Streaming - Real Time Speech Recognition Guide
|
We will start by creating a _full-context_ ASR demo, in which the user speaks the full audio before using the ASR model to run inference. This is very easy with Gradio -- we simply create a function around the `pipeline` object above.
We will use `gradio`'s built in `Audio` component, configured to take input from the user's microphone and return a filepath for the recorded audio. The output component will be a plain `Textbox`.
$code_asr
$demo_asr
The `transcribe` function takes a single parameter, `audio`, which is a numpy array of the audio the user recorded. The `pipeline` object expects this in float32 format, so we convert it first to float32, and then extract the transcribed text.
|
2. Create a Full-Context ASR Demo with Transformers
|
https://gradio.app/guides/real-time-speech-recognition
|
Streaming - Real Time Speech Recognition Guide
|
To make this a *streaming* demo, we need to make these changes:
1. Set `streaming=True` in the `Audio` component
2. Set `live=True` in the `Interface`
3. Add a `state` to the interface to store the recorded audio of a user
Tip: You can also set `time_limit` and `stream_every` parameters in the interface. The `time_limit` caps the amount of time each user's stream can take. The default is 30 seconds so users won't be able to stream audio for more than 30 seconds. The `stream_every` parameter controls how frequently data is sent to your function. By default it is 0.5 seconds.
Take a look below.
$code_stream_asr
Notice that we now have a state variable because we need to track all the audio history. `transcribe` gets called whenever there is a new small chunk of audio, but we also need to keep track of all the audio spoken so far in the state. As the interface runs, the `transcribe` function gets called, with a record of all the previously spoken audio in the `stream` and the new chunk of audio as `new_chunk`. We return the new full audio to be stored back in its current state, and we also return the transcription. Here, we naively append the audio together and call the `transcriber` object on the entire audio. You can imagine more efficient ways of handling this, such as re-processing only the last 5 seconds of audio whenever a new chunk of audio is received.
$demo_stream_asr
Now the ASR model will run inference as you speak!
|
3. Create a Streaming ASR Demo with Transformers
|
https://gradio.app/guides/real-time-speech-recognition
|
Streaming - Real Time Speech Recognition Guide
|
The next generation of AI user interfaces is moving towards audio-native experiences. Users will be able to speak to chatbots and receive spoken responses in return. Several models have been built under this paradigm, including GPT-4o and [mini omni](https://github.com/gpt-omni/mini-omni).
In this guide, we'll walk you through building your own conversational chat application using mini omni as an example. You can see a demo of the finished app below:
<video src="https://github.com/user-attachments/assets/db36f4db-7535-49f1-a2dd-bd36c487ebdf" controls
height="600" width="600" style="display: block; margin: auto;" autoplay="true" loop="true">
</video>
|
Introduction
|
https://gradio.app/guides/conversational-chatbot
|
Streaming - Conversational Chatbot Guide
|
Our application will enable the following user experience:
1. Users click a button to start recording their message
2. The app detects when the user has finished speaking and stops recording
3. The user's audio is passed to the omni model, which streams back a response
4. After omni mini finishes speaking, the user's microphone is reactivated
5. All previous spoken audio, from both the user and omni, is displayed in a chatbot component
Let's dive into the implementation details.
|
Application Overview
|
https://gradio.app/guides/conversational-chatbot
|
Streaming - Conversational Chatbot Guide
|
We'll stream the user's audio from their microphone to the server and determine if the user has stopped speaking on each new chunk of audio.
Here's our `process_audio` function:
```python
import numpy as np
from utils import determine_pause
def process_audio(audio: tuple, state: AppState):
if state.stream is None:
state.stream = audio[1]
state.sampling_rate = audio[0]
else:
state.stream = np.concatenate((state.stream, audio[1]))
pause_detected = determine_pause(state.stream, state.sampling_rate, state)
state.pause_detected = pause_detected
if state.pause_detected and state.started_talking:
return gr.Audio(recording=False), state
return None, state
```
This function takes two inputs:
1. The current audio chunk (a tuple of `(sampling_rate, numpy array of audio)`)
2. The current application state
We'll use the following `AppState` dataclass to manage our application state:
```python
from dataclasses import dataclass
@dataclass
class AppState:
stream: np.ndarray | None = None
sampling_rate: int = 0
pause_detected: bool = False
stopped: bool = False
conversation: list = []
```
The function concatenates new audio chunks to the existing stream and checks if the user has stopped speaking. If a pause is detected, it returns an update to stop recording. Otherwise, it returns `None` to indicate no changes.
The implementation of the `determine_pause` function is specific to the omni-mini project and can be found [here](https://huggingface.co/spaces/gradio/omni-mini/blob/eb027808c7bfe5179b46d9352e3fa1813a45f7c3/app.pyL98).
|
Processing User Audio
|
https://gradio.app/guides/conversational-chatbot
|
Streaming - Conversational Chatbot Guide
|
After processing the user's audio, we need to generate and stream the chatbot's response. Here's our `response` function:
```python
import io
import tempfile
from pydub import AudioSegment
def response(state: AppState):
if not state.pause_detected and not state.started_talking:
return None, AppState()
audio_buffer = io.BytesIO()
segment = AudioSegment(
state.stream.tobytes(),
frame_rate=state.sampling_rate,
sample_width=state.stream.dtype.itemsize,
channels=(1 if len(state.stream.shape) == 1 else state.stream.shape[1]),
)
segment.export(audio_buffer, format="wav")
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
f.write(audio_buffer.getvalue())
state.conversation.append({"role": "user",
"content": {"path": f.name,
"mime_type": "audio/wav"}})
output_buffer = b""
for mp3_bytes in speaking(audio_buffer.getvalue()):
output_buffer += mp3_bytes
yield mp3_bytes, state
with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as f:
f.write(output_buffer)
state.conversation.append({"role": "assistant",
"content": {"path": f.name,
"mime_type": "audio/mp3"}})
yield None, AppState(conversation=state.conversation)
```
This function:
1. Converts the user's audio to a WAV file
2. Adds the user's message to the conversation history
3. Generates and streams the chatbot's response using the `speaking` function
4. Saves the chatbot's response as an MP3 file
5. Adds the chatbot's response to the conversation history
Note: The implementation of the `speaking` function is specific to the omni-mini project and can be found [here](https://huggingface.co/spaces/gradio/omni-mini/blob/main/app.pyL116).
|
Generating the Response
|
https://gradio.app/guides/conversational-chatbot
|
Streaming - Conversational Chatbot Guide
|
Now let's put it all together using Gradio's Blocks API:
```python
import gradio as gr
def start_recording_user(state: AppState):
if not state.stopped:
return gr.Audio(recording=True)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
input_audio = gr.Audio(
label="Input Audio", sources="microphone", type="numpy"
)
with gr.Column():
chatbot = gr.Chatbot(label="Conversation")
output_audio = gr.Audio(label="Output Audio", streaming=True, autoplay=True)
state = gr.State(value=AppState())
stream = input_audio.stream(
process_audio,
[input_audio, state],
[input_audio, state],
stream_every=0.5,
time_limit=30,
)
respond = input_audio.stop_recording(
response,
[state],
[output_audio, state]
)
respond.then(lambda s: s.conversation, [state], [chatbot])
restart = output_audio.stop(
start_recording_user,
[state],
[input_audio]
)
cancel = gr.Button("Stop Conversation", variant="stop")
cancel.click(lambda: (AppState(stopped=True), gr.Audio(recording=False)), None,
[state, input_audio], cancels=[respond, restart])
if __name__ == "__main__":
demo.launch()
```
This setup creates a user interface with:
- An input audio component for recording user messages
- A chatbot component to display the conversation history
- An output audio component for the chatbot's responses
- A button to stop and reset the conversation
The app streams user audio in 0.5-second chunks, processes it, generates responses, and updates the conversation history accordingly.
|
Building the Gradio App
|
https://gradio.app/guides/conversational-chatbot
|
Streaming - Conversational Chatbot Guide
|
This guide demonstrates how to build a conversational chatbot application using Gradio and the mini omni model. You can adapt this framework to create various audio-based chatbot demos. To see the full application in action, visit the Hugging Face Spaces demo: https://huggingface.co/spaces/gradio/omni-mini
Feel free to experiment with different models, audio processing techniques, or user interface designs to create your own unique conversational AI experiences!
|
Conclusion
|
https://gradio.app/guides/conversational-chatbot
|
Streaming - Conversational Chatbot Guide
|
First, we'll install the following requirements in our system:
```
opencv-python
torch
transformers>=4.43.0
spaces
```
Then, we'll download the model from the Hugging Face Hub:
```python
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd").to("cuda")
```
We're moving the model to the GPU. We'll be deploying our model to Hugging Face Spaces and running the inference in the [free ZeroGPU cluster](https://huggingface.co/zero-gpu-explorers).
|
Setting up the Model
|
https://gradio.app/guides/object-detection-from-video
|
Streaming - Object Detection From Video Guide
|
Our inference function will accept a video and a desired confidence threshold.
Object detection models identify many objects and assign a confidence score to each object. The lower the confidence, the higher the chance of a false positive. So we will let our users set the confidence threshold.
Our function will iterate over the frames in the video and run the RT-DETR model over each frame.
We will then draw the bounding boxes for each detected object in the frame and save the frame to a new output video.
The function will yield each output video in chunks of two seconds.
In order to keep inference times as low as possible on ZeroGPU (there is a time-based quota),
we will halve the original frames-per-second in the output video and resize the input frames to be half the original
size before running the model.
The code for the inference function is below - we'll go over it piece by piece.
```python
import spaces
import cv2
from PIL import Image
import torch
import time
import numpy as np
import uuid
from draw_boxes import draw_bounding_boxes
SUBSAMPLE = 2
@spaces.GPU
def stream_object_detection(video, conf_threshold):
cap = cv2.VideoCapture(video)
This means we will output mp4 videos
video_codec = cv2.VideoWriter_fourcc(*"mp4v") type: ignore
fps = int(cap.get(cv2.CAP_PROP_FPS))
desired_fps = fps // SUBSAMPLE
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) // 2
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) // 2
iterating, frame = cap.read()
n_frames = 0
Use UUID to create a unique video file
output_video_name = f"output_{uuid.uuid4()}.mp4"
Output Video
output_video = cv2.VideoWriter(output_video_name, video_codec, desired_fps, (width, height)) type: ignore
batch = []
while iterating:
frame = cv2.resize( frame, (0,0), fx=0.5, fy=0.5)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if n_frames % SUBSAMPLE == 0:
batch.append(frame)
if len(batc
|
The Inference Function
|
https://gradio.app/guides/object-detection-from-video
|
Streaming - Object Detection From Video Guide
|
frame = cv2.resize( frame, (0,0), fx=0.5, fy=0.5)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if n_frames % SUBSAMPLE == 0:
batch.append(frame)
if len(batch) == 2 * desired_fps:
inputs = image_processor(images=batch, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model(**inputs)
boxes = image_processor.post_process_object_detection(
outputs,
target_sizes=torch.tensor([(height, width)] * len(batch)),
threshold=conf_threshold)
for i, (array, box) in enumerate(zip(batch, boxes)):
pil_image = draw_bounding_boxes(Image.fromarray(array), box, model, conf_threshold)
frame = np.array(pil_image)
Convert RGB to BGR
frame = frame[:, :, ::-1].copy()
output_video.write(frame)
batch = []
output_video.release()
yield output_video_name
output_video_name = f"output_{uuid.uuid4()}.mp4"
output_video = cv2.VideoWriter(output_video_name, video_codec, desired_fps, (width, height)) type: ignore
iterating, frame = cap.read()
n_frames += 1
```
1. **Reading from the Video**
One of the industry standards for creating videos in python is OpenCV so we will use it in this app.
The `cap` variable is how we will read from the input video. Whenever we call `cap.read()`, we are reading the next frame in the video.
In order to stream video in Gradio, we need to yield a different video file for each "chunk" of the output video.
We create the next video file to write to with the `output_video = cv2.VideoWriter(output_video_name, video_codec, desired_fps, (width, height))` line. The `video_codec` is how we specify the type of video file. Only "mp4" and "ts" files are supported for video sreaming at the moment.
2. **The Inference Loop**
For each frame i
|
The Inference Function
|
https://gradio.app/guides/object-detection-from-video
|
Streaming - Object Detection From Video Guide
|
dth, height))` line. The `video_codec` is how we specify the type of video file. Only "mp4" and "ts" files are supported for video sreaming at the moment.
2. **The Inference Loop**
For each frame in the video, we will resize it to be half the size. OpenCV reads files in `BGR` format, so will convert to the expected `RGB` format of transfomers. That's what the first two lines of the while loop are doing.
We take every other frame and add it to a `batch` list so that the output video is half the original FPS. When the batch covers two seconds of video, we will run the model. The two second threshold was chosen to keep the processing time of each batch small enough so that video is smoothly displayed in the server while not requiring too many separate forward passes. In order for video streaming to work properly in Gradio, the batch size should be at least 1 second.
We run the forward pass of the model and then use the `post_process_object_detection` method of the model to scale the detected bounding boxes to the size of the input frame.
We make use of a custom function to draw the bounding boxes (source [here](https://huggingface.co/spaces/gradio/rt-detr-object-detection/blob/main/draw_boxes.pyL14)). We then have to convert from `RGB` to `BGR` before writing back to the output video.
Once we have finished processing the batch, we create a new output video file for the next batch.
|
The Inference Function
|
https://gradio.app/guides/object-detection-from-video
|
Streaming - Object Detection From Video Guide
|
The UI code is pretty similar to other kinds of Gradio apps.
We'll use a standard two-column layout so that users can see the input and output videos side by side.
In order for streaming to work, we have to set `streaming=True` in the output video. Setting the video
to autoplay is not necessary but it's a better experience for users.
```python
import gradio as gr
with gr.Blocks() as app:
gr.HTML(
"""
<h1 style='text-align: center'>
Video Object Detection with <a href='https://huggingface.co/PekingU/rtdetr_r101vd_coco_o365' target='_blank'>RT-DETR</a>
</h1>
""")
with gr.Row():
with gr.Column():
video = gr.Video(label="Video Source")
conf_threshold = gr.Slider(
label="Confidence Threshold",
minimum=0.0,
maximum=1.0,
step=0.05,
value=0.30,
)
with gr.Column():
output_video = gr.Video(label="Processed Video", streaming=True, autoplay=True)
video.upload(
fn=stream_object_detection,
inputs=[video, conf_threshold],
outputs=[output_video],
)
```
|
The Gradio Demo
|
https://gradio.app/guides/object-detection-from-video
|
Streaming - Object Detection From Video Guide
|
You can check out our demo hosted on Hugging Face Spaces [here](https://huggingface.co/spaces/gradio/rt-detr-object-detection).
It is also embedded on this page below
$demo_rt-detr-object-detection
|
Conclusion
|
https://gradio.app/guides/object-detection-from-video
|
Streaming - Object Detection From Video Guide
|
Modern voice applications should feel natural and responsive, moving beyond the traditional "click-to-record" pattern. By combining Groq's fast inference capabilities with automatic speech detection, we can create a more intuitive interaction model where users can simply start talking whenever they want to engage with the AI.
> Credits: VAD and Gradio code inspired by [WillHeld's Diva-audio-chat](https://huggingface.co/spaces/WillHeld/diva-audio-chat/tree/main).
In this tutorial, you will learn how to create a multimodal Gradio and Groq app that has automatic speech detection. You can also watch the full video tutorial which includes a demo of the application:
<iframe width="560" height="315" src="https://www.youtube.com/embed/azXaioGdm2Q" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
|
Introduction
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
Many voice apps currently work by the user clicking record, speaking, then stopping the recording. While this can be a powerful demo, the most natural mode of interaction with voice requires the app to dynamically detect when the user is speaking, so they can talk back and forth without having to continually click a record button.
Creating a natural interaction with voice and text requires a dynamic and low-latency response. Thus, we need both automatic voice detection and fast inference. With @ricky0123/vad-web powering speech detection and Groq powering the LLM, both of these requirements are met. Groq provides a lightning fast response, and Gradio allows for easy creation of impressively functional apps.
This tutorial shows you how to build a calorie tracking app where you speak to an AI that automatically detects when you start and stop your response, and provides its own text response back to guide you with questions that allow it to give a calorie estimate of your last meal.
|
Background
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
- **Gradio**: Provides the web interface and audio handling capabilities
- **@ricky0123/vad-web**: Handles voice activity detection
- **Groq**: Powers fast LLM inference for natural conversations
- **Whisper**: Transcribes speech to text
Setting Up the Environment
First, let’s install and import our essential libraries and set up a client for using the Groq API. Here’s how to do it:
`requirements.txt`
```
gradio
groq
numpy
soundfile
librosa
spaces
xxhash
datasets
```
`app.py`
```python
import groq
import gradio as gr
import soundfile as sf
from dataclasses import dataclass, field
import os
Initialize Groq client securely
api_key = os.environ.get("GROQ_API_KEY")
if not api_key:
raise ValueError("Please set the GROQ_API_KEY environment variable.")
client = groq.Client(api_key=api_key)
```
Here, we’re pulling in key libraries to interact with the Groq API, build a sleek UI with Gradio, and handle audio data. We’re accessing the Groq API key securely with a key stored in an environment variable, which is a security best practice for avoiding leaking the API key.
---
State Management for Seamless Conversations
We need a way to keep track of our conversation history, so the chatbot remembers past interactions, and manage other states like whether recording is currently active. To do this, let’s create an `AppState` class:
```python
@dataclass
class AppState:
conversation: list = field(default_factory=list)
stopped: bool = False
model_outs: Any = None
```
Our `AppState` class is a handy tool for managing conversation history and tracking whether recording is on or off. Each instance will have its own fresh list of conversations, making sure chat history is isolated to each session.
---
Transcribing Audio with Whisper on Groq
Next, we’ll create a function to transcribe the user’s audio input into text using Whisper, a powerful transcription model hosted on Groq. This transcription will also help us determine whether there’s meani
|
Key Components
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
e’ll create a function to transcribe the user’s audio input into text using Whisper, a powerful transcription model hosted on Groq. This transcription will also help us determine whether there’s meaningful speech in the input. Here’s how:
```python
def transcribe_audio(client, file_name):
if file_name is None:
return None
try:
with open(file_name, "rb") as audio_file:
response = client.audio.transcriptions.with_raw_response.create(
model="whisper-large-v3-turbo",
file=("audio.wav", audio_file),
response_format="verbose_json",
)
completion = process_whisper_response(response.parse())
return completion
except Exception as e:
print(f"Error in transcription: {e}")
return f"Error in transcription: {str(e)}"
```
This function opens the audio file and sends it to Groq’s Whisper model for transcription, requesting detailed JSON output. verbose_json is needed to get information to determine if speech was included in the audio. We also handle any potential errors so our app doesn’t fully crash if there’s an issue with the API request.
```python
def process_whisper_response(completion):
"""
Process Whisper transcription response and return text or null based on no_speech_prob
Args:
completion: Whisper transcription response object
Returns:
str or None: Transcribed text if no_speech_prob <= 0.7, otherwise None
"""
if completion.segments and len(completion.segments) > 0:
no_speech_prob = completion.segments[0].get('no_speech_prob', 0)
print("No speech prob:", no_speech_prob)
if no_speech_prob > 0.7:
return None
return completion.text.strip()
return None
```
We also need to interpret the audio data response. The process_whisper_response function takes the resulting completion from Whisper and checks if the audio was j
|
Key Components
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
ext.strip()
return None
```
We also need to interpret the audio data response. The process_whisper_response function takes the resulting completion from Whisper and checks if the audio was just background noise or had actual speaking that was transcribed. It uses a threshold of 0.7 to interpret the no_speech_prob, and will return None if there was no speech. Otherwise, it will return the text transcript of the conversational response from the human.
---
Adding Conversational Intelligence with LLM Integration
Our chatbot needs to provide intelligent, friendly responses that flow naturally. We’ll use a Groq-hosted Llama-3.2 for this:
```python
def generate_chat_completion(client, history):
messages = []
messages.append(
{
"role": "system",
"content": "In conversation with the user, ask questions to estimate and provide (1) total calories, (2) protein, carbs, and fat in grams, (3) fiber and sugar content. Only ask *one question at a time*. Be conversational and natural.",
}
)
for message in history:
messages.append(message)
try:
completion = client.chat.completions.create(
model="llama-3.2-11b-vision-preview",
messages=messages,
)
return completion.choices[0].message.content
except Exception as e:
return f"Error in generating chat completion: {str(e)}"
```
We’re defining a system prompt to guide the chatbot’s behavior, ensuring it asks one question at a time and keeps things conversational. This setup also includes error handling to ensure the app gracefully manages any issues.
---
Voice Activity Detection for Hands-Free Interaction
To make our chatbot hands-free, we’ll add Voice Activity Detection (VAD) to automatically detect when someone starts or stops speaking. Here’s how to implement it using ONNX in JavaScript:
```javascript
async function main() {
const script1 = document.createElement("script");
scrip
|
Key Components
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
ly detect when someone starts or stops speaking. Here’s how to implement it using ONNX in JavaScript:
```javascript
async function main() {
const script1 = document.createElement("script");
script1.src = "https://cdn.jsdelivr.net/npm/onnxruntime-web@1.14.0/dist/ort.js";
document.head.appendChild(script1)
const script2 = document.createElement("script");
script2.onload = async () => {
console.log("vad loaded");
var record = document.querySelector('.record-button');
record.textContent = "Just Start Talking!"
const myvad = await vad.MicVAD.new({
onSpeechStart: () => {
var record = document.querySelector('.record-button');
var player = document.querySelector('streaming-out')
if (record != null && (player == null || player.paused)) {
record.click();
}
},
onSpeechEnd: (audio) => {
var stop = document.querySelector('.stop-button');
if (stop != null) {
stop.click();
}
}
})
myvad.start()
}
script2.src = "https://cdn.jsdelivr.net/npm/@ricky0123/vad-web@0.0.7/dist/bundle.min.js";
}
```
This script loads our VAD model and sets up functions to start and stop recording automatically. When the user starts speaking, it triggers the recording, and when they stop, it ends the recording.
---
Building a User Interface with Gradio
Now, let’s create an intuitive and visually appealing user interface with Gradio. This interface will include an audio input for capturing voice, a chat window for displaying responses, and state management to keep things synchronized.
```python
with gr.Blocks() as demo:
with gr.Row():
input_audio = gr.Audio(
label="Input Audio",
sources=["microphone"],
type="numpy",
streaming=False,
waveform_options=gr.WaveformOptions(waveform_color="B83A4B"),
)
with gr.Row():
chatbot = gr.Chatbot(label="Conversation")
state = g
|
Key Components
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
",
streaming=False,
waveform_options=gr.WaveformOptions(waveform_color="B83A4B"),
)
with gr.Row():
chatbot = gr.Chatbot(label="Conversation")
state = gr.State(value=AppState())
demo.launch(theme=theme, js=js)
```
In this code block, we’re using Gradio’s `Blocks` API to create an interface with an audio input, a chat display, and an application state manager. The color customization for the waveform adds a nice visual touch.
---
Handling Recording and Responses
Finally, let’s link the recording and response components to ensure the app reacts smoothly to user inputs and provides responses in real-time.
```python
stream = input_audio.start_recording(
process_audio,
[input_audio, state],
[input_audio, state],
)
respond = input_audio.stop_recording(
response, [state, input_audio], [state, chatbot]
)
```
These lines set up event listeners for starting and stopping the recording, processing the audio input, and generating responses. By linking these events, we create a cohesive experience where users can simply talk, and the chatbot handles the rest.
---
|
Key Components
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
1. When you open the app, the VAD system automatically initializes and starts listening for speech
2. As soon as you start talking, it triggers the recording automatically
3. When you stop speaking, the recording ends and:
- The audio is transcribed using Whisper
- The transcribed text is sent to the LLM
- The LLM generates a response about calorie tracking
- The response is displayed in the chat interface
4. This creates a natural back-and-forth conversation where you can simply talk about your meals and get instant feedback on nutritional content
This app demonstrates how to create a natural voice interface that feels responsive and intuitive. By combining Groq's fast inference with automatic speech detection, we've eliminated the need for manual recording controls while maintaining high-quality interactions. The result is a practical calorie tracking assistant that users can simply talk to as naturally as they would to a human nutritionist.
Link to GitHub repository: [Groq Gradio Basics](https://github.com/bklieger-groq/gradio-groq-basics/tree/main/calorie-tracker)
|
Summary
|
https://gradio.app/guides/automatic-voice-detection
|
Streaming - Automatic Voice Detection Guide
|
Adding examples to an Interface is as easy as providing a list of lists to the `examples`
keyword argument.
Each sublist is a data sample, where each element corresponds to an input of the prediction function.
The inputs must be ordered in the same order as the prediction function expects them.
If your interface only has one input component, then you can provide your examples as a regular list instead of a list of lists.
Loading Examples from a Directory
You can also specify a path to a directory containing your examples. If your Interface takes only a single file-type input, e.g. an image classifier, you can simply pass a directory filepath to the `examples=` argument, and the `Interface` will load the images in the directory as examples.
In the case of multiple inputs, this directory must
contain a log.csv file with the example values.
In the context of the calculator demo, we can set `examples='/demo/calculator/examples'` and in that directory we include the following `log.csv` file:
```csv
num,operation,num2
5,"add",3
4,"divide",2
5,"multiply",3
```
This can be helpful when browsing flagged data. Simply point to the flagged directory and the `Interface` will load the examples from the flagged data.
Providing Partial Examples
Sometimes your app has many input components, but you would only like to provide examples for a subset of them. In order to exclude some inputs from the examples, pass `None` for all data samples corresponding to those particular components.
|
Providing Examples
|
https://gradio.app/guides/more-on-examples
|
Building Interfaces - More On Examples Guide
|
You may wish to provide some cached examples of your model for users to quickly try out, in case your model takes a while to run normally.
If `cache_examples=True`, your Gradio app will run all of the examples and save the outputs when you call the `launch()` method. This data will be saved in a directory called `gradio_cached_examples` in your working directory by default. You can also set this directory with the `GRADIO_EXAMPLES_CACHE` environment variable, which can be either an absolute path or a relative path to your working directory.
Whenever a user clicks on an example, the output will automatically be populated in the app now, using data from this cached directory instead of actually running the function. This is useful so users can quickly try out your model without adding any load!
Alternatively, you can set `cache_examples="lazy"`. This means that each particular example will only get cached after it is first used (by any user) in the Gradio app. This is helpful if your prediction function is long-running and you do not want to wait a long time for your Gradio app to start.
Keep in mind once the cache is generated, it will not be updated automatically in future launches. If the examples or function logic change, delete the cache folder to clear the cache and rebuild it with another `launch()`.
|
Caching examples
|
https://gradio.app/guides/more-on-examples
|
Building Interfaces - More On Examples Guide
|
If the state is something that should be accessible to all function calls and all users, you can create a variable outside the function call and access it inside the function. For example, you may load a large model outside the function and use it inside the function so that every function call does not need to reload the model.
$code_score_tracker
In the code above, the `scores` array is shared between all users. If multiple users are accessing this demo, their scores will all be added to the same list, and the returned top 3 scores will be collected from this shared reference.
|
Global State
|
https://gradio.app/guides/interface-state
|
Building Interfaces - Interface State Guide
|
Another type of data persistence Gradio supports is session state, where data persists across multiple submits within a page session. However, data is _not_ shared between different users of your model. To store data in a session state, you need to do three things:
1. Pass in an extra parameter into your function, which represents the state of the interface.
2. At the end of the function, return the updated value of the state as an extra return value.
3. Add the `'state'` input and `'state'` output components when creating your `Interface`
Here's a simple app to illustrate session state - this app simply stores users previous submissions and displays them back to the user:
$code_interface_state
$demo_interface_state
Notice how the state persists across submits within each page, but if you load this demo in another tab (or refresh the page), the demos will not share chat history. Here, we could not store the submission history in a global variable, otherwise the submission history would then get jumbled between different users.
The initial value of the `State` is `None` by default. If you pass a parameter to the `value` argument of `gr.State()`, it is used as the default value of the state instead.
Note: the `Interface` class only supports a single session state variable (though it can be a list with multiple elements). For more complex use cases, you can use Blocks, [which supports multiple `State` variables](/guides/state-in-blocks/). Alternatively, if you are building a chatbot that maintains user state, consider using the `ChatInterface` abstraction, [which manages state automatically](/guides/creating-a-chatbot-fast).
|
Session State
|
https://gradio.app/guides/interface-state
|
Building Interfaces - Interface State Guide
|
To create a demo that has both the input and the output components, you simply need to set the values of the `inputs` and `outputs` parameter in `Interface()`. Here's an example demo of a simple image filter:
$code_sepia_filter
$demo_sepia_filter
|
Standard demos
|
https://gradio.app/guides/four-kinds-of-interfaces
|
Building Interfaces - Four Kinds Of Interfaces Guide
|
What about demos that only contain outputs? In order to build such a demo, you simply set the value of the `inputs` parameter in `Interface()` to `None`. Here's an example demo of a mock image generation model:
$code_fake_gan_no_input
$demo_fake_gan_no_input
|
Output-only demos
|
https://gradio.app/guides/four-kinds-of-interfaces
|
Building Interfaces - Four Kinds Of Interfaces Guide
|
Similarly, to create a demo that only contains inputs, set the value of `outputs` parameter in `Interface()` to be `None`. Here's an example demo that saves any uploaded image to disk:
$code_save_file_no_output
$demo_save_file_no_output
|
Input-only demos
|
https://gradio.app/guides/four-kinds-of-interfaces
|
Building Interfaces - Four Kinds Of Interfaces Guide
|
A demo that has a single component as both the input and the output. It can simply be created by setting the values of the `inputs` and `outputs` parameter as the same component. Here's an example demo of a text generation model:
$code_unified_demo_text_generation
$demo_unified_demo_text_generation
It may be the case that none of the 4 cases fulfill your exact needs. In this case, you need to use the `gr.Blocks()` approach!
|
Unified demos
|
https://gradio.app/guides/four-kinds-of-interfaces
|
Building Interfaces - Four Kinds Of Interfaces Guide
|
Gradio includes more than 30 pre-built components (as well as many [community-built _custom components_](https://www.gradio.app/custom-components/gallery)) that can be used as inputs or outputs in your demo. These components correspond to common data types in machine learning and data science, e.g. the `gr.Image` component is designed to handle input or output images, the `gr.Label` component displays classification labels and probabilities, the `gr.LinePlot` component displays line plots, and so on.
|
Gradio Components
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
We used the default versions of the `gr.Textbox` and `gr.Slider`, but what if you want to change how the UI components look or behave?
Let's say you want to customize the slider to have values from 1 to 10, with a default of 2. And you wanted to customize the output text field — you want it to be larger and have a label.
If you use the actual classes for `gr.Textbox` and `gr.Slider` instead of the string shortcuts, you have access to much more customizability through component attributes.
$code_hello_world_2
$demo_hello_world_2
|
Components Attributes
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
Suppose you had a more complex function, with multiple outputs as well. In the example below, we define a function that takes a string, boolean, and number, and returns a string and number.
$code_hello_world_3
$demo_hello_world_3
Just as each component in the `inputs` list corresponds to one of the parameters of the function, in order, each component in the `outputs` list corresponds to one of the values returned by the function, in order.
|
Multiple Input and Output Components
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
Gradio supports many types of components, such as `Image`, `DataFrame`, `Video`, or `Label`. Let's try an image-to-image function to get a feel for these!
$code_sepia_filter
$demo_sepia_filter
When using the `Image` component as input, your function will receive a NumPy array with the shape `(height, width, 3)`, where the last dimension represents the RGB values. We'll return an image as well in the form of a NumPy array.
Gradio handles the preprocessing and postprocessing to convert images to NumPy arrays and vice versa. You can also control the preprocessing performed with the `type=` keyword argument. For example, if you wanted your function to take a file path to an image instead of a NumPy array, the input `Image` component could be written as:
```python
gr.Image(type="filepath")
```
You can read more about the built-in Gradio components and how to customize them in the [Gradio docs](https://gradio.app/docs).
|
An Image Example
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
You can provide example data that a user can easily load into `Interface`. This can be helpful to demonstrate the types of inputs the model expects, as well as to provide a way to explore your dataset in conjunction with your model. To load example data, you can provide a **nested list** to the `examples=` keyword argument of the Interface constructor. Each sublist within the outer list represents a data sample, and each element within the sublist represents an input for each input component. The format of example data for each component is specified in the [Docs](https://gradio.app/docscomponents).
$code_calculator
$demo_calculator
You can load a large dataset into the examples to browse and interact with the dataset through Gradio. The examples will be automatically paginated (you can configure this through the `examples_per_page` argument of `Interface`).
Continue learning about examples in the [More On Examples](https://gradio.app/guides/more-on-examples) guide.
|
Example Inputs
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
In the previous example, you may have noticed the `title=` and `description=` keyword arguments in the `Interface` constructor that helps users understand your app.
There are three arguments in the `Interface` constructor to specify where this content should go:
- `title`: which accepts text and can display it at the very top of interface, and also becomes the page title.
- `description`: which accepts text, markdown or HTML and places it right under the title.
- `article`: which also accepts text, markdown or HTML and places it below the interface.

Another useful keyword argument is `label=`, which is present in every `Component`. This modifies the label text at the top of each `Component`. You can also add the `info=` keyword argument to form elements like `Textbox` or `Radio` to provide further information on their usage.
```python
gr.Number(label='Age', info='In years, must be greater than 0')
```
|
Descriptive Content
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
If your prediction function takes many inputs, you may want to hide some of them within a collapsed accordion to avoid cluttering the UI. The `Interface` class takes an `additional_inputs` argument which is similar to `inputs` but any input components included here are not visible by default. The user must click on the accordion to show these components. The additional inputs are passed into the prediction function, in order, after the standard inputs.
You can customize the appearance of the accordion by using the optional `additional_inputs_accordion` argument, which accepts a string (in which case, it becomes the label of the accordion), or an instance of the `gr.Accordion()` class (e.g. this lets you control whether the accordion is open or closed by default).
Here's an example:
$code_interface_with_additional_inputs
$demo_interface_with_additional_inputs
|
Additional Inputs within an Accordion
|
https://gradio.app/guides/the-interface-class
|
Building Interfaces - The Interface Class Guide
|
You can make interfaces automatically refresh by setting `live=True` in the interface. Now the interface will recalculate as soon as the user input changes.
$code_calculator_live
$demo_calculator_live
Note there is no submit button, because the interface resubmits automatically on change.
|
Live Interfaces
|
https://gradio.app/guides/reactive-interfaces
|
Building Interfaces - Reactive Interfaces Guide
|
Some components have a "streaming" mode, such as `Audio` component in microphone mode, or the `Image` component in webcam mode. Streaming means data is sent continuously to the backend and the `Interface` function is continuously being rerun.
The difference between `gr.Audio(source='microphone')` and `gr.Audio(source='microphone', streaming=True)`, when both are used in `gr.Interface(live=True)`, is that the first `Component` will automatically submit data and run the `Interface` function when the user stops recording, whereas the second `Component` will continuously send data and run the `Interface` function _during_ recording.
Here is example code of streaming images from the webcam.
$code_stream_frames
Streaming can also be done in an output component. A `gr.Audio(streaming=True)` output component can take a stream of audio data yielded piece-wise by a generator function and combines them into a single audio file. For a detailed example, see our guide on performing [automatic speech recognition](/guides/real-time-speech-recognition) with Gradio.
|
Streaming Components
|
https://gradio.app/guides/reactive-interfaces
|
Building Interfaces - Reactive Interfaces Guide
|
Let's start with what seems like the most complex bit -- using machine learning to remove the music from a video.
Luckily for us, there's an existing Space we can use to make this process easier: [https://huggingface.co/spaces/abidlabs/music-separation](https://huggingface.co/spaces/abidlabs/music-separation). This Space takes an audio file and produces two separate audio files: one with the instrumental music and one with all other sounds in the original clip. Perfect to use with our client!
Open a new Python file, say `main.py`, and start by importing the `Client` class from `gradio_client` and connecting it to this Space:
```py
from gradio_client import Client, handle_file
client = Client("abidlabs/music-separation")
def acapellify(audio_path):
result = client.predict(handle_file(audio_path), api_name="/predict")
return result[0]
```
That's all the code that's needed -- notice that the API endpoints returns two audio files (one without the music, and one with just the music) in a list, and so we just return the first element of the list.
---
**Note**: since this is a public Space, there might be other users using this Space as well, which might result in a slow experience. You can duplicate this Space with your own [Hugging Face token](https://huggingface.co/settings/tokens) and create a private Space that only you have will have access to and bypass the queue. To do that, simply replace the first two lines above with:
```py
from gradio_client import Client
client = Client.duplicate("abidlabs/music-separation", token=YOUR_HF_TOKEN)
```
Everything else remains the same!
---
Now, of course, we are working with video files, so we first need to extract the audio from the video files. For this, we will be using the `ffmpeg` library, which does a lot of heavy lifting when it comes to working with audio and video files. The most common way to use `ffmpeg` is through the command line, which we'll call via Python's `subprocess` module:
Our video proc
|
Step 1: Write the Video Processing Function
|
https://gradio.app/guides/fastapi-app-with-the-gradio-client
|
Gradio Clients And Lite - Fastapi App With The Gradio Client Guide
|
f heavy lifting when it comes to working with audio and video files. The most common way to use `ffmpeg` is through the command line, which we'll call via Python's `subprocess` module:
Our video processing workflow will consist of three steps:
1. First, we start by taking in a video filepath and extracting the audio using `ffmpeg`.
2. Then, we pass in the audio file through the `acapellify()` function above.
3. Finally, we combine the new audio with the original video to produce a final acapellified video.
Here's the complete code in Python, which you can add to your `main.py` file:
```python
import subprocess
def process_video(video_path):
old_audio = os.path.basename(video_path).split(".")[0] + ".m4a"
subprocess.run(['ffmpeg', '-y', '-i', video_path, '-vn', '-acodec', 'copy', old_audio])
new_audio = acapellify(old_audio)
new_video = f"acap_{video_path}"
subprocess.call(['ffmpeg', '-y', '-i', video_path, '-i', new_audio, '-map', '0:v', '-map', '1:a', '-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental', f"static/{new_video}"])
return new_video
```
You can read up on [ffmpeg documentation](https://ffmpeg.org/ffmpeg.html) if you'd like to understand all of the command line parameters, as they are beyond the scope of this tutorial.
|
Step 1: Write the Video Processing Function
|
https://gradio.app/guides/fastapi-app-with-the-gradio-client
|
Gradio Clients And Lite - Fastapi App With The Gradio Client Guide
|
Next up, we'll create a simple FastAPI app. If you haven't used FastAPI before, check out [the great FastAPI docs](https://fastapi.tiangolo.com/). Otherwise, this basic template, which we add to `main.py`, will look pretty familiar:
```python
import os
from fastapi import FastAPI, File, UploadFile, Request
from fastapi.responses import HTMLResponse, RedirectResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
app = FastAPI()
os.makedirs("static", exist_ok=True)
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
videos = []
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse(
"home.html", {"request": request, "videos": videos})
@app.post("/uploadvideo/")
async def upload_video(video: UploadFile = File(...)):
video_path = video.filename
with open(video_path, "wb+") as fp:
fp.write(video.file.read())
new_video = process_video(video.filename)
videos.append(new_video)
return RedirectResponse(url='/', status_code=303)
```
In this example, the FastAPI app has two routes: `/` and `/uploadvideo/`.
The `/` route returns an HTML template that displays a gallery of all uploaded videos.
The `/uploadvideo/` route accepts a `POST` request with an `UploadFile` object, which represents the uploaded video file. The video file is "acapellified" via the `process_video()` method, and the output video is stored in a list which stores all of the uploaded videos in memory.
Note that this is a very basic example and if this were a production app, you will need to add more logic to handle file storage, user authentication, and security considerations.
|
Step 2: Create a FastAPI app (Backend Routes)
|
https://gradio.app/guides/fastapi-app-with-the-gradio-client
|
Gradio Clients And Lite - Fastapi App With The Gradio Client Guide
|
Finally, we create the frontend of our web application. First, we create a folder called `templates` in the same directory as `main.py`. We then create a template, `home.html` inside the `templates` folder. Here is the resulting file structure:
```csv
├── main.py
├── templates
│ └── home.html
```
Write the following as the contents of `home.html`:
```html
<!DOCTYPE html> <html> <head> <title>Video Gallery</title>
<style> body { font-family: sans-serif; margin: 0; padding: 0;
background-color: f5f5f5; } h1 { text-align: center; margin-top: 30px;
margin-bottom: 20px; } .gallery { display: flex; flex-wrap: wrap;
justify-content: center; gap: 20px; padding: 20px; } .video { border: 2px solid
ccc; box-shadow: 0px 0px 10px rgba(0, 0, 0, 0.2); border-radius: 5px; overflow:
hidden; width: 300px; margin-bottom: 20px; } .video video { width: 100%; height:
200px; } .video p { text-align: center; margin: 10px 0; } form { margin-top:
20px; text-align: center; } input[type="file"] { display: none; } .upload-btn {
display: inline-block; background-color: 3498db; color: fff; padding: 10px
20px; font-size: 16px; border: none; border-radius: 5px; cursor: pointer; }
.upload-btn:hover { background-color: 2980b9; } .file-name { margin-left: 10px;
} </style> </head> <body> <h1>Video Gallery</h1> {% if videos %}
<div class="gallery"> {% for video in videos %} <div class="video">
<video controls> <source src="{{ url_for('static', path=video) }}"
type="video/mp4"> Your browser does not support the video tag. </video>
<p>{{ video }}</p> </div> {% endfor %} </div> {% else %} <p>No
videos uploaded yet.</p> {% endif %} <form action="/uploadvideo/"
method="post" enctype="multipart/form-data"> <label for="video-upload"
class="upload-btn">Choose video file</label> <input type="file"
name="video" id="video-upload"> <span class="file-name"></span> <button
type="submit" class="upload-btn">Upload</butto
|
Step 3: Create a FastAPI app (Frontend Template)
|
https://gradio.app/guides/fastapi-app-with-the-gradio-client
|
Gradio Clients And Lite - Fastapi App With The Gradio Client Guide
|
class="upload-btn">Choose video file</label> <input type="file"
name="video" id="video-upload"> <span class="file-name"></span> <button
type="submit" class="upload-btn">Upload</button> </form> <script> //
Display selected file name in the form const fileUpload =
document.getElementById("video-upload"); const fileName =
document.querySelector(".file-name"); fileUpload.addEventListener("change", (e)
=> { fileName.textContent = e.target.files[0].name; }); </script> </body>
</html>
```
|
Step 3: Create a FastAPI app (Frontend Template)
|
https://gradio.app/guides/fastapi-app-with-the-gradio-client
|
Gradio Clients And Lite - Fastapi App With The Gradio Client Guide
|
Finally, we are ready to run our FastAPI app, powered by the Gradio Python Client!
Open up a terminal and navigate to the directory containing `main.py`. Then run the following command in the terminal:
```bash
$ uvicorn main:app
```
You should see an output that looks like this:
```csv
Loaded as API: https://abidlabs-music-separation.hf.space ✔
INFO: Started server process [1360]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
And that's it! Start uploading videos and you'll get some "acapellified" videos in response (might take seconds to minutes to process depending on the length of your videos). Here's how the UI looks after uploading two videos:
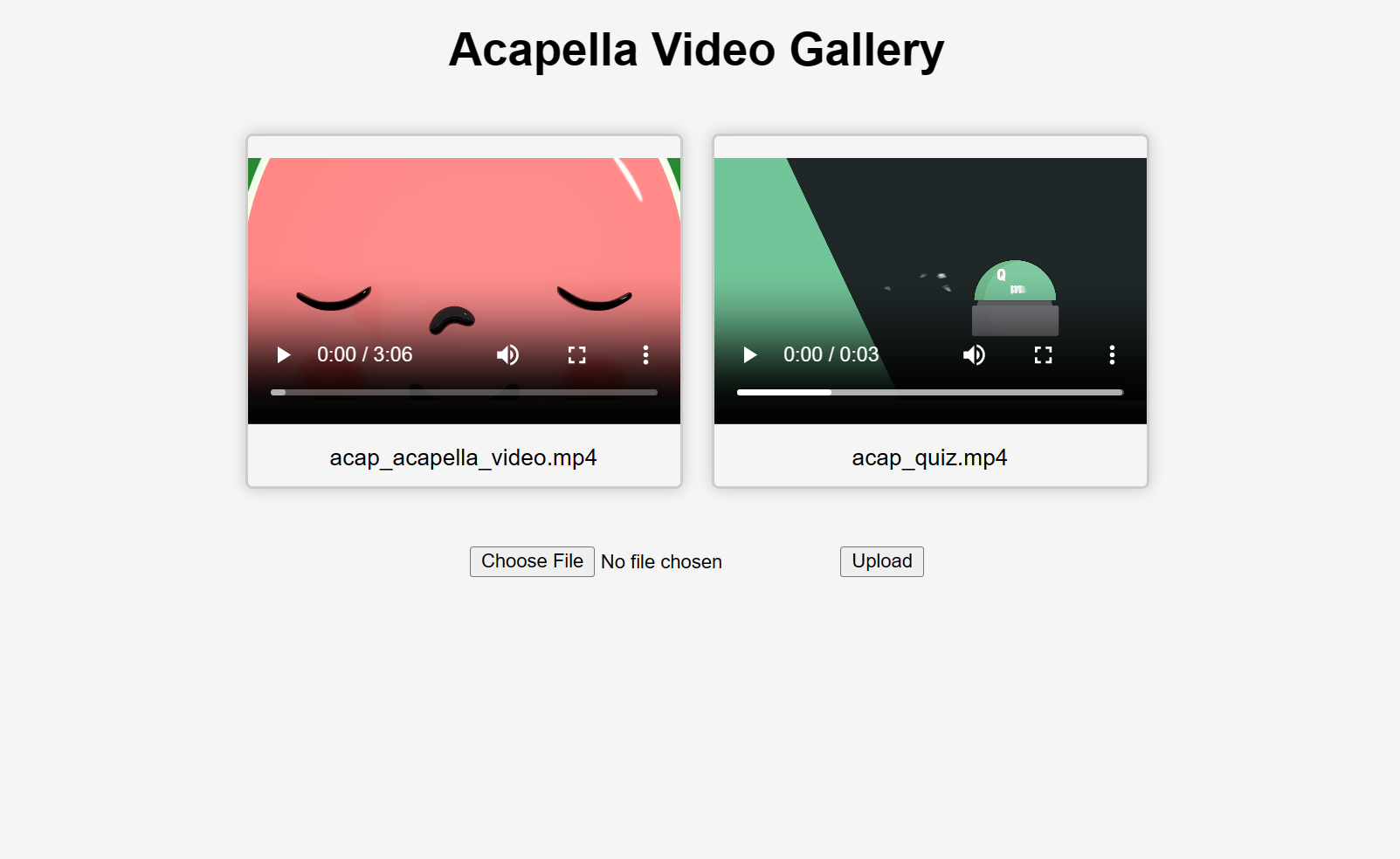
If you'd like to learn more about how to use the Gradio Python Client in your projects, [read the dedicated Guide](/guides/getting-started-with-the-python-client/).
|
Step 4: Run your FastAPI app
|
https://gradio.app/guides/fastapi-app-with-the-gradio-client
|
Gradio Clients And Lite - Fastapi App With The Gradio Client Guide
|
If you already have a recent version of `gradio`, then the `gradio_client` is included as a dependency. But note that this documentation reflects the latest version of the `gradio_client`, so upgrade if you're not sure!
The lightweight `gradio_client` package can be installed from pip (or pip3) and is tested to work with **Python versions 3.10 or higher**:
```bash
$ pip install --upgrade gradio_client
```
|
Installation
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
Start by connecting instantiating a `Client` object and connecting it to a Gradio app that is running on Hugging Face Spaces.
```python
from gradio_client import Client
client = Client("abidlabs/en2fr") a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `token` parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```python
from gradio_client import Client
client = Client("abidlabs/my-private-space", token="...")
```
|
Connecting to a Gradio App on Hugging Face Spaces
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space,
and then use it to make as many requests as you'd like!
The `gradio_client` includes a class method: `Client.duplicate()` to make this process simple (you'll need to pass in your [Hugging Face token](https://huggingface.co/settings/tokens) or be logged in using the Hugging Face CLI):
```python
import os
from gradio_client import Client, handle_file
HF_TOKEN = os.environ.get("HF_TOKEN")
client = Client.duplicate("abidlabs/whisper", token=HF_TOKEN)
client.predict(handle_file("audio_sample.wav"))
>> "This is a test of the whisper speech recognition model."
```
If you have previously duplicated a Space, re-running `duplicate()` will _not_ create a new Space. Instead, the Client will attach to the previously-created Space. So it is safe to re-run the `Client.duplicate()` method multiple times.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 1 hour of inactivity. You can also set the hardware using the `hardware` parameter of `duplicate()`.
|
Duplicating a Space for private use
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```python
from gradio_client import Client
client = Client("https://bec81a83-5b5c-471e.gradio.live")
```
|
Connecting a general Gradio app
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
If the Gradio application you are connecting to [requires a username and password](/guides/sharing-your-appauthentication), then provide them as a tuple to the `auth` argument of the `Client` class:
```python
from gradio_client import Client
Client(
space_name,
auth=[username, password]
)
```
|
Connecting to a Gradio app with auth
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `Client.view_api()` method. For the Whisper Space, we see the following:
```bash
Client.predict() Usage Info
---------------------------
Named API endpoints: 1
- predict(audio, api_name="/predict") -> output
Parameters:
- [Audio] audio: filepath (required)
Returns:
- [Textbox] output: str
```
We see that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method (which we will explore below), providing a parameter `input_audio` of type `str`, which is a `filepath or URL`.
We should also provide the `api_name='/predict'` argument to the `predict()` method. Although this isn't necessary if a Gradio app has only 1 named endpoint, it does allow us to call different endpoints in a single app if they are available.
|
Inspecting the API endpoints
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
As an alternative to running the `.view_api()` method, you can click on the "Use via API" link in the footer of the Gradio app, which shows us the same information, along with example usage.
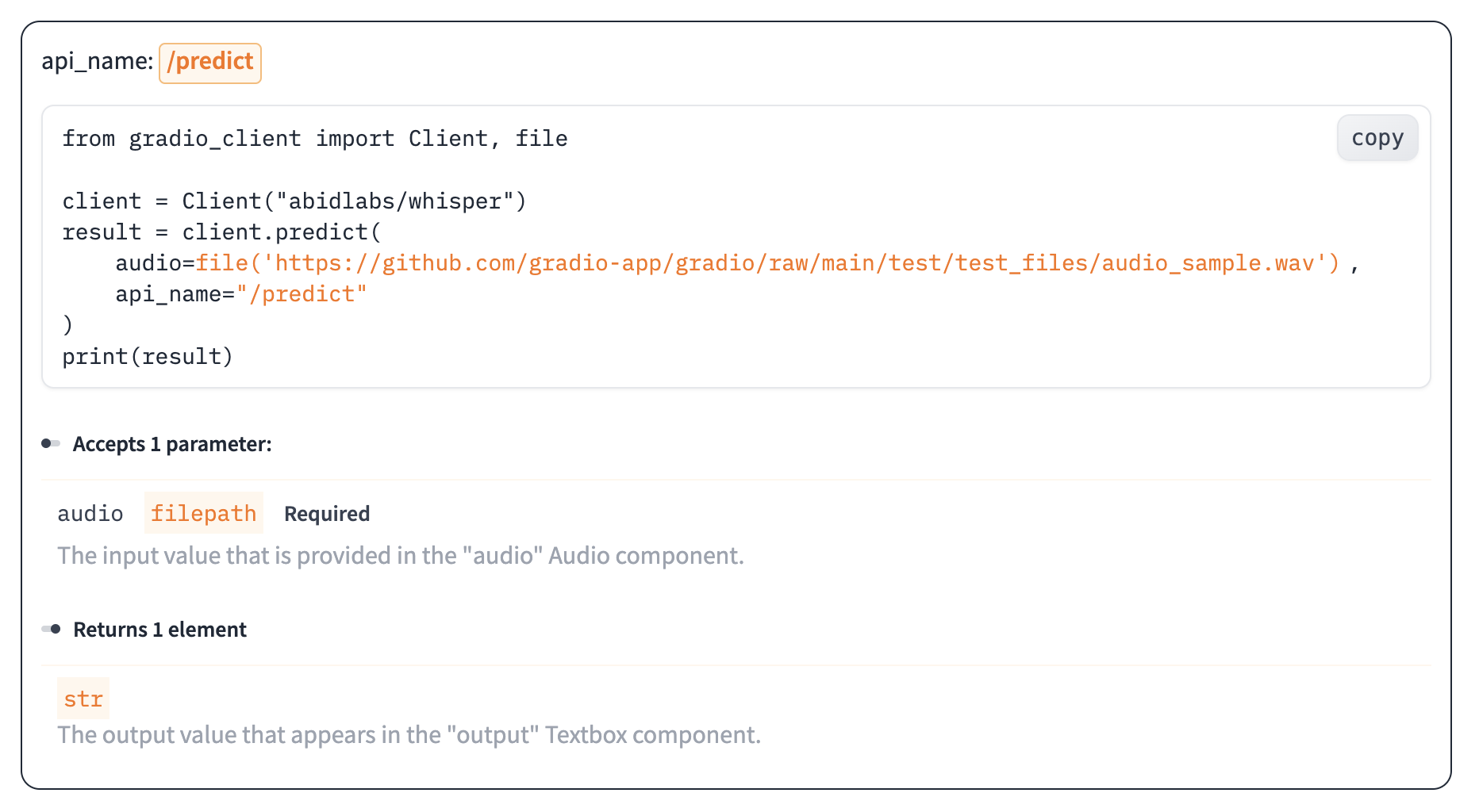
The View API page also includes an "API Recorder" that lets you interact with the Gradio UI normally and converts your interactions into the corresponding code to run with the Python Client.
|
The "View API" Page
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
The simplest way to make a prediction is simply to call the `.predict()` function with the appropriate arguments:
```python
from gradio_client import Client
client = Client("abidlabs/en2fr")
client.predict("Hello", api_name='/predict')
>> Bonjour
```
If there are multiple parameters, then you should pass them as separate arguments to `.predict()`, like this:
```python
from gradio_client import Client
client = Client("gradio/calculator")
client.predict(4, "add", 5)
>> 9.0
```
It is recommended to provide key-word arguments instead of positional arguments:
```python
from gradio_client import Client
client = Client("gradio/calculator")
client.predict(num1=4, operation="add", num2=5)
>> 9.0
```
This allows you to take advantage of default arguments. For example, this Space includes the default value for the Slider component so you do not need to provide it when accessing it with the client.
```python
from gradio_client import Client
client = Client("abidlabs/image_generator")
client.predict(text="an astronaut riding a camel")
```
The default value is the initial value of the corresponding Gradio component. If the component does not have an initial value, but if the corresponding argument in the predict function has a default value of `None`, then that parameter is also optional in the client. Of course, if you'd like to override it, you can include it as well:
```python
from gradio_client import Client
client = Client("abidlabs/image_generator")
client.predict(text="an astronaut riding a camel", steps=25)
```
For providing files or URLs as inputs, you should pass in the filepath or URL to the file enclosed within `gradio_client.handle_file()`. This takes care of uploading the file to the Gradio server and ensures that the file is preprocessed correctly:
```python
from gradio_client import Client, handle_file
client = Client("abidlabs/whisper")
client.predict(
audio=handle_file("https://audio-samples.github.io/samples/mp3/blizzard_unconditional/s
|
Making a prediction
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
```python
from gradio_client import Client, handle_file
client = Client("abidlabs/whisper")
client.predict(
audio=handle_file("https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3")
)
>> "My thought I have nobody by a beauty and will as you poured. Mr. Rochester is serve in that so don't find simpus, and devoted abode, to at might in a r—"
```
|
Making a prediction
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
One should note that `.predict()` is a _blocking_ operation as it waits for the operation to complete before returning the prediction.
In many cases, you may be better off letting the job run in the background until you need the results of the prediction. You can do this by creating a `Job` instance using the `.submit()` method, and then later calling `.result()` on the job to get the result. For example:
```python
from gradio_client import Client
client = Client(space="abidlabs/en2fr")
job = client.submit("Hello", api_name="/predict") This is not blocking
Do something else
job.result() This is blocking
>> Bonjour
```
|
Running jobs asynchronously
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
Alternatively, one can add one or more callbacks to perform actions after the job has completed running, like this:
```python
from gradio_client import Client
def print_result(x):
print("The translated result is: {x}")
client = Client(space="abidlabs/en2fr")
job = client.submit("Hello", api_name="/predict", result_callbacks=[print_result])
Do something else
>> The translated result is: Bonjour
```
|
Adding callbacks
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
The `Job` object also allows you to get the status of the running job by calling the `.status()` method. This returns a `StatusUpdate` object with the following attributes: `code` (the status code, one of a set of defined strings representing the status. See the `utils.Status` class), `rank` (the current position of this job in the queue), `queue_size` (the total queue size), `eta` (estimated time this job will complete), `success` (a boolean representing whether the job completed successfully), and `time` (the time that the status was generated).
```py
from gradio_client import Client
client = Client(src="gradio/calculator")
job = client.submit(5, "add", 4, api_name="/predict")
job.status()
>> <Status.STARTING: 'STARTING'>
```
_Note_: The `Job` class also has a `.done()` instance method which returns a boolean indicating whether the job has completed.
|
Status
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
The `Job` class also has a `.cancel()` instance method that cancels jobs that have been queued but not started. For example, if you run:
```py
client = Client("abidlabs/whisper")
job1 = client.submit(handle_file("audio_sample1.wav"))
job2 = client.submit(handle_file("audio_sample2.wav"))
job1.cancel() will return False, assuming the job has started
job2.cancel() will return True, indicating that the job has been canceled
```
If the first job has started processing, then it will not be canceled. If the second job
has not yet started, it will be successfully canceled and removed from the queue.
|
Cancelling Jobs
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
Some Gradio API endpoints do not return a single value, rather they return a series of values. You can get the series of values that have been returned at any time from such a generator endpoint by running `job.outputs()`:
```py
from gradio_client import Client
client = Client(src="gradio/count_generator")
job = client.submit(3, api_name="/count")
while not job.done():
time.sleep(0.1)
job.outputs()
>> ['0', '1', '2']
```
Note that running `job.result()` on a generator endpoint only gives you the _first_ value returned by the endpoint.
The `Job` object is also iterable, which means you can use it to display the results of a generator function as they are returned from the endpoint. Here's the equivalent example using the `Job` as a generator:
```py
from gradio_client import Client
client = Client(src="gradio/count_generator")
job = client.submit(3, api_name="/count")
for o in job:
print(o)
>> 0
>> 1
>> 2
```
You can also cancel jobs that that have iterative outputs, in which case the job will finish as soon as the current iteration finishes running.
```py
from gradio_client import Client
import time
client = Client("abidlabs/test-yield")
job = client.submit("abcdef")
time.sleep(3)
job.cancel() job cancels after 2 iterations
```
|
Generator Endpoints
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
Gradio demos can include [session state](https://www.gradio.app/guides/state-in-blocks), which provides a way for demos to persist information from user interactions within a page session.
For example, consider the following demo, which maintains a list of words that a user has submitted in a `gr.State` component. When a user submits a new word, it is added to the state, and the number of previous occurrences of that word is displayed:
```python
import gradio as gr
def count(word, list_of_words):
return list_of_words.count(word), list_of_words + [word]
with gr.Blocks() as demo:
words = gr.State([])
textbox = gr.Textbox()
number = gr.Number()
textbox.submit(count, inputs=[textbox, words], outputs=[number, words])
demo.launch()
```
If you were to connect this this Gradio app using the Python Client, you would notice that the API information only shows a single input and output:
```csv
Client.predict() Usage Info
---------------------------
Named API endpoints: 1
- predict(word, api_name="/count") -> value_31
Parameters:
- [Textbox] word: str (required)
Returns:
- [Number] value_31: float
```
That is because the Python client handles state automatically for you -- as you make a series of requests, the returned state from one request is stored internally and automatically supplied for the subsequent request. If you'd like to reset the state, you can do that by calling `Client.reset_session()`.
|
Demos with Session State
|
https://gradio.app/guides/getting-started-with-the-python-client
|
Gradio Clients And Lite - Getting Started With The Python Client Guide
|
You generally don't need to install cURL, as it comes pre-installed on many operating systems. Run:
```bash
curl --version
```
to confirm that `curl` is installed. If it is not already installed, you can install it by visiting https://curl.se/download.html.
|
Installation
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
To query a Gradio app, you'll need its full URL. This is usually just the URL that the Gradio app is hosted on, for example: https://bec81a83-5b5c-471e.gradio.live
**Hugging Face Spaces**
However, if you are querying a Gradio on Hugging Face Spaces, you will need to use the URL of the embedded Gradio app, not the URL of the Space webpage. For example:
```bash
❌ Space URL: https://huggingface.co/spaces/abidlabs/en2fr
✅ Gradio app URL: https://abidlabs-en2fr.hf.space/
```
You can get the Gradio app URL by clicking the "view API" link at the bottom of the page. Or, you can right-click on the page and then click on "View Frame Source" or the equivalent in your browser to view the URL of the embedded Gradio app.
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space,
and then use it to make as many requests as you'd like!
Note: to query private Spaces, you will need to pass in your Hugging Face (HF) token. You can get your HF token here: https://huggingface.co/settings/tokens. In this case, you will need to include an additional header in both of your `curl` calls that we'll discuss below:
```bash
-H "Authorization: Bearer $HF_TOKEN"
```
Now, we are ready to make the two `curl` requests.
|
Step 0: Get the URL for your Gradio App
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
The first of the two `curl` requests is `POST` request that submits the input payload to the Gradio app.
The syntax of the `POST` request is as follows:
```bash
$ curl -X POST $URL/call/$API_NAME -H "Content-Type: application/json" -d '{
"data": $PAYLOAD
}'
```
Here:
* `$URL` is the URL of the Gradio app as obtained in Step 0
* `$API_NAME` is the name of the API endpoint for the event that you are running. You can get the API endpoint names by clicking the "view API" link at the bottom of the page.
* `$PAYLOAD` is a valid JSON data list containing the input payload, one element for each input component.
When you make this `POST` request successfully, you will get an event id that is printed to the terminal in this format:
```bash
>> {"event_id": $EVENT_ID}
```
This `EVENT_ID` will be needed in the subsequent `curl` request to fetch the results of the prediction.
Here are some examples of how to make the `POST` request
**Basic Example**
Revisiting the example at the beginning of the page, here is how to make the `POST` request for a simple Gradio application that takes in a single input text component:
```bash
$ curl -X POST https://abidlabs-en2fr.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": ["Hello, my friend."]
}'
```
**Multiple Input Components**
This [Gradio demo](https://huggingface.co/spaces/gradio/hello_world_3) accepts three inputs: a string corresponding to the `gr.Textbox`, a boolean value corresponding to the `gr.Checkbox`, and a numerical value corresponding to the `gr.Slider`. Here is the `POST` request:
```bash
curl -X POST https://gradio-hello-world-3.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": ["Hello", true, 5]
}'
```
**Private Spaces**
As mentioned earlier, if you are making a request to a private Space, you will need to pass in a [Hugging Face token](https://huggingface.co/settings/tokens) that has read access to the Space. The request will look like this:
```bash
|
Step 1: Make a Prediction (POST)
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
king a request to a private Space, you will need to pass in a [Hugging Face token](https://huggingface.co/settings/tokens) that has read access to the Space. The request will look like this:
```bash
$ curl -X POST https://private-space.hf.space/call/predict -H "Content-Type: application/json" -H "Authorization: Bearer $HF_TOKEN" -d '{
"data": ["Hello, my friend."]
}'
```
**Files**
If you are using `curl` to query a Gradio application that requires file inputs, the files *need* to be provided as URLs, and The URL needs to be enclosed in a dictionary in this format:
```bash
{"path": $URL}
```
Here is an example `POST` request:
```bash
$ curl -X POST https://gradio-image-mod.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": [{"path": "https://raw.githubusercontent.com/gradio-app/gradio/main/test/test_files/bus.png"}]
}'
```
**Stateful Demos**
If your Gradio demo [persists user state](/guides/interface-state) across multiple interactions (e.g. is a chatbot), you can pass in a `session_hash` alongside the `data`. Requests with the same `session_hash` are assumed to be part of the same user session. Here's how that might look:
```bash
These two requests will share a session
curl -X POST https://gradio-chatinterface-random-response.hf.space/call/chat -H "Content-Type: application/json" -d '{
"data": ["Are you sentient?"],
"session_hash": "randomsequence1234"
}'
curl -X POST https://gradio-chatinterface-random-response.hf.space/call/chat -H "Content-Type: application/json" -d '{
"data": ["Really?"],
"session_hash": "randomsequence1234"
}'
This request will be treated as a new session
curl -X POST https://gradio-chatinterface-random-response.hf.space/call/chat -H "Content-Type: application/json" -d '{
"data": ["Are you sentient?"],
"session_hash": "newsequence5678"
}'
```
|
Step 1: Make a Prediction (POST)
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
ient?"],
"session_hash": "newsequence5678"
}'
```
|
Step 1: Make a Prediction (POST)
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
Once you have received the `EVENT_ID` corresponding to your prediction, you can stream the results. Gradio stores these results in a least-recently-used cache in the Gradio app. By default, the cache can store 2,000 results (across all users and endpoints of the app).
To stream the results for your prediction, make a `GET` request with the following syntax:
```bash
$ curl -N $URL/call/$API_NAME/$EVENT_ID
```
Tip: If you are fetching results from a private Space, include a header with your HF token like this: `-H "Authorization: Bearer $HF_TOKEN"` in the `GET` request.
This should produce a stream of responses in this format:
```bash
event: ...
data: ...
event: ...
data: ...
...
```
Here: `event` can be one of the following:
* `generating`: indicating an intermediate result
* `complete`: indicating that the prediction is complete and the final result
* `error`: indicating that the prediction was not completed successfully
* `heartbeat`: sent every 15 seconds to keep the request alive
The `data` is in the same format as the input payload: valid JSON data list containing the output result, one element for each output component.
Here are some examples of what results you should expect if a request is completed successfully:
**Basic Example**
Revisiting the example at the beginning of the page, we would expect the result to look like this:
```bash
event: complete
data: ["Bonjour, mon ami."]
```
**Multiple Outputs**
If your endpoint returns multiple values, they will appear as elements of the `data` list:
```bash
event: complete
data: ["Good morning Hello. It is 5 degrees today", -15.0]
```
**Streaming Example**
If your Gradio app [streams a sequence of values](/guides/streaming-outputs), then they will be streamed directly to your terminal, like this:
```bash
event: generating
data: ["Hello, w!"]
event: generating
data: ["Hello, wo!"]
event: generating
data: ["Hello, wor!"]
event: generating
data: ["Hello, worl!"]
event: generating
data: ["Hello, w
|
Step 2: GET the result
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
```bash
event: generating
data: ["Hello, w!"]
event: generating
data: ["Hello, wo!"]
event: generating
data: ["Hello, wor!"]
event: generating
data: ["Hello, worl!"]
event: generating
data: ["Hello, world!"]
event: complete
data: ["Hello, world!"]
```
**File Example**
If your Gradio app returns a file, the file will be represented as a dictionary in this format (including potentially some additional keys):
```python
{
"orig_name": "example.jpg",
"path": "/path/in/server.jpg",
"url": "https:/example.com/example.jpg",
"meta": {"_type": "gradio.FileData"}
}
```
In your terminal, it may appear like this:
```bash
event: complete
data: [{"path": "/tmp/gradio/359933dc8d6cfe1b022f35e2c639e6e42c97a003/image.webp", "url": "https://gradio-image-mod.hf.space/c/file=/tmp/gradio/359933dc8d6cfe1b022f35e2c639e6e42c97a003/image.webp", "size": null, "orig_name": "image.webp", "mime_type": null, "is_stream": false, "meta": {"_type": "gradio.FileData"}}]
```
|
Step 2: GET the result
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
What if your Gradio application has [authentication enabled](/guides/sharing-your-appauthentication)? In that case, you'll need to make an additional `POST` request with cURL to authenticate yourself before you make any queries. Here are the complete steps:
First, login with a `POST` request supplying a valid username and password:
```bash
curl -X POST $URL/login \
-d "username=$USERNAME&password=$PASSWORD" \
-c cookies.txt
```
If the credentials are correct, you'll get `{"success":true}` in response and the cookies will be saved in `cookies.txt`.
Next, you'll need to include these cookies when you make the original `POST` request, like this:
```bash
$ curl -X POST $URL/call/$API_NAME -b cookies.txt -H "Content-Type: application/json" -d '{
"data": $PAYLOAD
}'
```
Finally, you'll need to `GET` the results, again supplying the cookies from the file:
```bash
curl -N $URL/call/$API_NAME/$EVENT_ID -b cookies.txt
```
|
Authentication
|
https://gradio.app/guides/querying-gradio-apps-with-curl
|
Gradio Clients And Lite - Querying Gradio Apps With Curl Guide
|
Install the @gradio/client package to interact with Gradio APIs using Node.js version >=18.0.0 or in browser-based projects. Use npm or any compatible package manager:
```bash
npm i @gradio/client
```
This command adds @gradio/client to your project dependencies, allowing you to import it in your JavaScript or TypeScript files.
|
Installation via npm
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
For quick addition to your web project, you can use the jsDelivr CDN to load the latest version of @gradio/client directly into your HTML:
```html
<script type="module">
import { Client } from "https://cdn.jsdelivr.net/npm/@gradio/client/dist/index.min.js";
...
</script>
```
Be sure to add this to the `<head>` of your HTML. This will install the latest version but we advise hardcoding the version in production. You can find all available versions [here](https://www.jsdelivr.com/package/npm/@gradio/client). This approach is ideal for experimental or prototying purposes, though has some limitations. A complete example would look like this:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<script type="module">
import { Client } from "https://cdn.jsdelivr.net/npm/@gradio/client/dist/index.min.js";
const client = await Client.connect("abidlabs/en2fr");
const result = await client.predict("/predict", {
text: "My name is Hannah"
});
console.log(result);
</script>
</head>
</html>
```
|
Installation via CDN
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
Start by connecting instantiating a `client` instance and connecting it to a Gradio app that is running on Hugging Face Spaces or generally anywhere on the web.
|
Connecting to a running Gradio App
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr"); // a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `token` property of the options parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/my-private-space", { token: "hf_..." })
```
|
Connecting to a Hugging Face Space
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space, and then use it to make as many requests as you'd like! You'll need to pass in your [Hugging Face token](https://huggingface.co/settings/tokens)).
`Client.duplicate` is almost identical to `Client.connect`, the only difference is under the hood:
```js
import { Client, handle_file } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await Client.duplicate("abidlabs/whisper", { token: "hf_..." });
const transcription = await app.predict("/predict", [handle_file(audio_file)]);
```
If you have previously duplicated a Space, re-running `Client.duplicate` will _not_ create a new Space. Instead, the client will attach to the previously-created Space. So it is safe to re-run the `Client.duplicate` method multiple times with the same space.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 5 minutes of inactivity. You can also set the hardware using the `hardware` and `timeout` properties of `duplicate`'s options object like this:
```js
import { Client } from "@gradio/client";
const app = await Client.duplicate("abidlabs/whisper", {
token: "hf_...",
timeout: 60,
hardware: "a10g-small"
});
```
|
Duplicating a Space for private use
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```js
import { Client } from "@gradio/client";
const app = Client.connect("https://bec81a83-5b5c-471e.gradio.live");
```
|
Connecting a general Gradio app
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
If the Gradio application you are connecting to [requires a username and password](/guides/sharing-your-appauthentication), then provide them as a tuple to the `auth` argument of the `Client` class:
```js
import { Client } from "@gradio/client";
Client.connect(
space_name,
{ auth: [username, password] }
)
```
|
Connecting to a Gradio app with auth
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `Client`'s `view_api` method.
For the Whisper Space, we can do this:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/whisper");
const app_info = await app.view_api();
console.log(app_info);
```
And we will see the following:
```json
{
"named_endpoints": {
"/predict": {
"parameters": [
{
"label": "text",
"component": "Textbox",
"type": "string"
}
],
"returns": [
{
"label": "output",
"component": "Textbox",
"type": "string"
}
]
}
},
"unnamed_endpoints": {}
}
```
This shows us that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method (which we will explore below), providing a parameter `input_audio` of type `string`, which is a url to a file.
We should also provide the `api_name='/predict'` argument to the `predict()` method. Although this isn't necessary if a Gradio app has only 1 named endpoint, it does allow us to call different endpoints in a single app if they are available. If an app has unnamed API endpoints, these can also be displayed by running `.view_api(all_endpoints=True)`.
|
Inspecting the API endpoints
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
As an alternative to running the `.view_api()` method, you can click on the "Use via API" link in the footer of the Gradio app, which shows us the same information, along with example usage.

The View API page also includes an "API Recorder" that lets you interact with the Gradio UI normally and converts your interactions into the corresponding code to run with the JS Client.
|
The "View API" Page
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
The simplest way to make a prediction is simply to call the `.predict()` method with the appropriate arguments:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr");
const result = await app.predict("/predict", ["Hello"]);
```
If there are multiple parameters, then you should pass them as an array to `.predict()`, like this:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("gradio/calculator");
const result = await app.predict("/predict", [4, "add", 5]);
```
For certain inputs, such as images, you should pass in a `Buffer`, `Blob` or `File` depending on what is most convenient. In node, this would be a `Buffer` or `Blob`; in a browser environment, this would be a `Blob` or `File`.
```js
import { Client, handle_file } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await Client.connect("abidlabs/whisper");
const result = await app.predict("/predict", [handle_file(audio_file)]);
```
|
Making a prediction
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
If the API you are working with can return results over time, or you wish to access information about the status of a job, you can use the iterable interface for more flexibility. This is especially useful for iterative endpoints or generator endpoints that will produce a series of values over time as discrete responses.
```js
import { Client } from "@gradio/client";
function log_result(payload) {
const {
data: [translation]
} = payload;
console.log(`The translated result is: ${translation}`);
}
const app = await Client.connect("abidlabs/en2fr");
const job = app.submit("/predict", ["Hello"]);
for await (const message of job) {
log_result(message);
}
```
|
Using events
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
The event interface also allows you to get the status of the running job by instantiating the client with the `events` options passing `status` and `data` as an array:
```ts
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr", {
events: ["status", "data"]
});
```
This ensures that status messages are also reported to the client.
`status`es are returned as an object with the following attributes: `status` (a human readbale status of the current job, `"pending" | "generating" | "complete" | "error"`), `code` (the detailed gradio code for the job), `position` (the current position of this job in the queue), `queue_size` (the total queue size), `eta` (estimated time this job will complete), `success` (a boolean representing whether the job completed successfully), and `time` ( as `Date` object detailing the time that the status was generated).
```js
import { Client } from "@gradio/client";
function log_status(status) {
console.log(
`The current status for this job is: ${JSON.stringify(status, null, 2)}.`
);
}
const app = await Client.connect("abidlabs/en2fr", {
events: ["status", "data"]
});
const job = app.submit("/predict", ["Hello"]);
for await (const message of job) {
if (message.type === "status") {
log_status(message);
}
}
```
|
Status
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
The job instance also has a `.cancel()` method that cancels jobs that have been queued but not started. For example, if you run:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr");
const job_one = app.submit("/predict", ["Hello"]);
const job_two = app.submit("/predict", ["Friends"]);
job_one.cancel();
job_two.cancel();
```
If the first job has started processing, then it will not be canceled but the client will no longer listen for updates (throwing away the job). If the second job has not yet started, it will be successfully canceled and removed from the queue.
|
Cancelling Jobs
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
Some Gradio API endpoints do not return a single value, rather they return a series of values. You can listen for these values in real time using the iterable interface:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("gradio/count_generator");
const job = app.submit(0, [9]);
for await (const message of job) {
console.log(message.data);
}
```
This will log out the values as they are generated by the endpoint.
You can also cancel jobs that that have iterative outputs, in which case the job will finish immediately.
```js
import { Client } from "@gradio/client";
const app = await Client.connect("gradio/count_generator");
const job = app.submit(0, [9]);
for await (const message of job) {
console.log(message.data);
}
setTimeout(() => {
job.cancel();
}, 3000);
```
|
Generator Endpoints
|
https://gradio.app/guides/getting-started-with-the-js-client
|
Gradio Clients And Lite - Getting Started With The Js Client Guide
|
What are agents?
A [LangChain agent](https://docs.langchain.com/docs/components/agents/agent) is a Large Language Model (LLM) that takes user input and reports an output based on using one of many tools at its disposal.
What is Gradio?
[Gradio](https://github.com/gradio-app/gradio) is the defacto standard framework for building Machine Learning Web Applications and sharing them with the world - all with just python! 🐍
|
Some background
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
To get started with `gradio_tools`, all you need to do is import and initialize your tools and pass them to the langchain agent!
In the following example, we import the `StableDiffusionPromptGeneratorTool` to create a good prompt for stable diffusion, the
`StableDiffusionTool` to create an image with our improved prompt, the `ImageCaptioningTool` to caption the generated image, and
the `TextToVideoTool` to create a video from a prompt.
We then tell our agent to create an image of a dog riding a skateboard, but to please improve our prompt ahead of time. We also ask
it to caption the generated image and create a video for it. The agent can decide which tool to use without us explicitly telling it.
```python
import os
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY must be set")
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from gradio_tools import (StableDiffusionTool, ImageCaptioningTool, StableDiffusionPromptGeneratorTool,
TextToVideoTool)
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history")
tools = [StableDiffusionTool().langchain, ImageCaptioningTool().langchain,
StableDiffusionPromptGeneratorTool().langchain, TextToVideoTool().langchain]
agent = initialize_agent(tools, llm, memory=memory, agent="conversational-react-description", verbose=True)
output = agent.run(input=("Please create a photo of a dog riding a skateboard "
"but improve my prompt prior to using an image generator."
"Please caption the generated image and create a video for it using the improved prompt."))
```
You'll note that we are using some pre-built tools that come with `gradio_tools`. Please see this [doc](https://github.com/freddyaboulton/gradio-toolsgradio-tools-gradio--llm-agents) for a complete list of the tools that come with `gradio_tools`.
If
|
gradio_tools - An end-to-end example
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
that come with `gradio_tools`. Please see this [doc](https://github.com/freddyaboulton/gradio-toolsgradio-tools-gradio--llm-agents) for a complete list of the tools that come with `gradio_tools`.
If you would like to use a tool that's not currently in `gradio_tools`, it is very easy to add your own. That's what the next section will cover.
|
gradio_tools - An end-to-end example
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
The core abstraction is the `GradioTool`, which lets you define a new tool for your LLM as long as you implement a standard interface:
```python
class GradioTool(BaseTool):
def __init__(self, name: str, description: str, src: str) -> None:
@abstractmethod
def create_job(self, query: str) -> Job:
pass
@abstractmethod
def postprocess(self, output: Tuple[Any] | Any) -> str:
pass
```
The requirements are:
1. The name for your tool
2. The description for your tool. This is crucial! Agents decide which tool to use based on their description. Be precise and be sure to include example of what the input and the output of the tool should look like.
3. The url or space id, e.g. `freddyaboulton/calculator`, of the Gradio application. Based on this value, `gradio_tool` will create a [gradio client](https://github.com/gradio-app/gradio/blob/main/client/python/README.md) instance to query the upstream application via API. Be sure to click the link and learn more about the gradio client library if you are not familiar with it.
4. create_job - Given a string, this method should parse that string and return a job from the client. Most times, this is as simple as passing the string to the `submit` function of the client. More info on creating jobs [here](https://github.com/gradio-app/gradio/blob/main/client/python/README.mdmaking-a-prediction)
5. postprocess - Given the result of the job, convert it to a string the LLM can display to the user.
6. _Optional_ - Some libraries, e.g. [MiniChain](https://github.com/srush/MiniChain/tree/main), may need some info about the underlying gradio input and output types used by the tool. By default, this will return gr.Textbox() but
if you'd like to provide more accurate info, implement the `_block_input(self, gr)` and `_block_output(self, gr)` methods of the tool. The `gr` variable is the gradio module (the result of `import gradio as gr`). It will be
automatically imported by the `GradiTool` parent
|
gradio_tools - creating your own tool
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
lf, gr)` and `_block_output(self, gr)` methods of the tool. The `gr` variable is the gradio module (the result of `import gradio as gr`). It will be
automatically imported by the `GradiTool` parent class and passed to the `_block_input` and `_block_output` methods.
And that's it!
Once you have created your tool, open a pull request to the `gradio_tools` repo! We welcome all contributions.
|
gradio_tools - creating your own tool
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
Here is the code for the StableDiffusion tool as an example:
```python
from gradio_tool import GradioTool
import os
class StableDiffusionTool(GradioTool):
"""Tool for calling stable diffusion from llm"""
def __init__(
self,
name="StableDiffusion",
description=(
"An image generator. Use this to generate images based on "
"text input. Input should be a description of what the image should "
"look like. The output will be a path to an image file."
),
src="gradio-client-demos/stable-diffusion",
token=None,
) -> None:
super().__init__(name, description, src, token)
def create_job(self, query: str) -> Job:
return self.client.submit(query, "", 9, fn_index=1)
def postprocess(self, output: str) -> str:
return [os.path.join(output, i) for i in os.listdir(output) if not i.endswith("json")][0]
def _block_input(self, gr) -> "gr.components.Component":
return gr.Textbox()
def _block_output(self, gr) -> "gr.components.Component":
return gr.Image()
```
Some notes on this implementation:
1. All instances of `GradioTool` have an attribute called `client` that is a pointed to the underlying [gradio client](https://github.com/gradio-app/gradio/tree/main/client/pythongradio_client-use-a-gradio-app-as-an-api----in-3-lines-of-python). That is what you should use
in the `create_job` method.
2. `create_job` just passes the query string to the `submit` function of the client with some other parameters hardcoded, i.e. the negative prompt string and the guidance scale. We could modify our tool to also accept these values from the input string in a subsequent version.
3. The `postprocess` method simply returns the first image from the gallery of images created by the stable diffusion space. We use the `os` module to get the full path of the image.
|
Example tool - Stable Diffusion
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
You now know how to extend the abilities of your LLM with the 1000s of gradio spaces running in the wild!
Again, we welcome any contributions to the [gradio_tools](https://github.com/freddyaboulton/gradio-tools) library.
We're excited to see the tools you all build!
|
Conclusion
|
https://gradio.app/guides/gradio-and-llm-agents
|
Gradio Clients And Lite - Gradio And Llm Agents Guide
|
Take a look at the demo below.
$code_hello_blocks
$demo_hello_blocks
- First, note the `with gr.Blocks() as demo:` clause. The Blocks app code will be contained within this clause.
- Next come the Components. These are the same Components used in `Interface`. However, instead of being passed to some constructor, Components are automatically added to the Blocks as they are created within the `with` clause.
- Finally, the `click()` event listener. Event listeners define the data flow within the app. In the example above, the listener ties the two Textboxes together. The Textbox `name` acts as the input and Textbox `output` acts as the output to the `greet` method. This dataflow is triggered when the Button `greet_btn` is clicked. Like an Interface, an event listener can take multiple inputs or outputs.
You can also attach event listeners using decorators - skip the `fn` argument and assign `inputs` and `outputs` directly:
$code_hello_blocks_decorator
|
Blocks Structure
|
https://gradio.app/guides/blocks-and-event-listeners
|
Building With Blocks - Blocks And Event Listeners Guide
|
In the example above, you'll notice that you are able to edit Textbox `name`, but not Textbox `output`. This is because any Component that acts as an input to an event listener is made interactive. However, since Textbox `output` acts only as an output, Gradio determines that it should not be made interactive. You can override the default behavior and directly configure the interactivity of a Component with the boolean `interactive` keyword argument, e.g. `gr.Textbox(interactive=True)`.
```python
output = gr.Textbox(label="Output", interactive=True)
```
_Note_: What happens if a Gradio component is neither an input nor an output? If a component is constructed with a default value, then it is presumed to be displaying content and is rendered non-interactive. Otherwise, it is rendered interactive. Again, this behavior can be overridden by specifying a value for the `interactive` argument.
|
Event Listeners and Interactivity
|
https://gradio.app/guides/blocks-and-event-listeners
|
Building With Blocks - Blocks And Event Listeners Guide
|
Take a look at the demo below:
$code_blocks_hello
$demo_blocks_hello
Instead of being triggered by a click, the `welcome` function is triggered by typing in the Textbox `inp`. This is due to the `change()` event listener. Different Components support different event listeners. For example, the `Video` Component supports a `play()` event listener, triggered when a user presses play. See the [Docs](http://gradio.app/docscomponents) for the event listeners for each Component.
|
Types of Event Listeners
|
https://gradio.app/guides/blocks-and-event-listeners
|
Building With Blocks - Blocks And Event Listeners Guide
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.